|
http://sites.schaltungen.at/httrack/
Wels, am 2014-01-01BITTE nützen Sie doch rechts OBEN das Suchfeld [ ] [ Diese Site durchsuchen]DIN A3 oder DIN A4 quer ausdrucken
*******************************************************************************I** DIN A4 ausdrucken (Heftrand 15mm / 5mm) siehe http://sites.schaltungen.at/drucker/sites-prenninger
********************************************************I* ~015_b_PrennIng-a_httrack/ (xx Seiten)_1a.pdfWinHTTrack Website Copier Version 3.47-27(09.15.2013)
Ganze Websites offline speichern mit Open-Source-Software HTTrack.
Online-Inhalte offline abspeichern.
HTTrack Website Copier - Schritt-für-Schritt-Anleitung
(aber besser als die englische Beschreibung die kann ich ohne Englischkenntnisse nicht verstehen)
Willkommen beim WinHTTrack Website Copier!
MENU 1 Datei 2 Optionen 3 Site-Kopie 4 Protokoll 5 Fenster 5 Hilfe
HTTrack ist ein freie Software. Ein einfach zu bedienendes Offline-Browser-Dienstprogramm. Es ermöglicht einem, eine Internetseite aus dem World Wide Web in ein lokales Verzeichnis downzuloaden, Gebäude rekursiv alle Verzeichnisse, immer HTML, Bilder und andere Dateien vom Server auf Ihren Computer. HTTrack arrangiert relativen Link-Struktur des ursprünglichen Standorts. Öffnen Sie einfach eine Seite des "gespiegelt"-Website in Ihrem Browser, und Sie können die Website von Link zu Link durchsuchen, als ob Sie sie online betrachten. HTTrack kann auch eine bestehende gespiegelte Website zu aktualisieren und abgebrochene Downloads fortsetzen. HTTrack ist vollständig konfigurierbar und verfügt über ein integriertes Hilfesystem. WinHTTrack ist die Windows-Version von HTTrack für Betriebssystem win 95/98/NT/2000/XP/Vista/Win7/ Win8/ Win8.1 64bit
 HTTrack Überblick und Funktionen Inhaltsverzeichnis Dokumentation 1 Überblick HTTrack Überblick und Funktionen 2 FAQ & Troubleshooting Häufig gestellte Fragen zu HTTrack und Fehlerbehebung 3 So verwenden 3.1 WinHTTrack / webhttrack (GUI-Version für Windows oder Linux / Unix) HTTrack GUI-Dokumentation, mit Schritt-für-Schritt-Beispiel für die Windows-Version (WinHTTrack) und der Linux / Unix relese (webhttrack) 3.2 HTTrack Users Guide von Fred Cohen Ein Tutorial, das alle Befehlszeilenoptionen beschrieben, für Linux und Windows-Benutzer 3.3 Konstrukteurs / Programmierung Wie HTTrack in Batch-Dateien verwenden, und wie man die Bibliothek benutzen 4 Wie nicht zu verwenden Was Sie nicht tun dürfen: Bandbreite Missbrauch und andere schlechte Verhaltensweisen 5 Lizenz Die HTTrack Lizenzvereinbarung 6 Release-Wechsel Neue Funktionen und Bugfixes finden Sie hier 7 Über dieses Programm Wie Sie uns erreichen für Kommentare, Fehlerbericht und alles andere, Informationen zu diesem Projekt http://www.httrack.com/ Windows-Shell-Dokumentation Hinweis: WinHTTrack (Windows Version von HTTrack) und webhttrack (Linux / Unix-Version von HTTrack) sind sehr ähnlich, aber nicht genau gleich. Sie können kleinere Unterschiede (im Display oder in verschiedenen Optionen) zwischen diesen beiden Versionen auftreten. Der Motor hinter diesen beiden Mitteilung ist identisch. Schritt-für-Schritt-Beispiel von WinHTTrack Website Copier HTTrack GUI-Dokumentation, mit Schritt-für-Schritt-Beispiel für die Windows-Version (WinHTTrack) und der Linux / Unix relese (webhttrack) Schnellstart mit WinHTTrack / webhttrack **************************************************************************
Schritt 1: Wählen Sie einen Projektnamen und den Zielordner Projektname: z.B. LINKSAMMLUNG
Project categorie: fritz
Basisverzeichnis: C:Users\fritz\Desktop\HTTrack [ Weiter > ]1 Ändern Sie den Zielordner, wenn notwendig Es ist bequemer, alle Spiegel in einem Verzeichnis zu organisieren, beispielsweise Meine Websites Wenn Sie bereits Spiegeln mit HTTrack, achten Sie darauf, dass Sie den richtigen Ordner ausgewählt haben.
In welchem ORDNER sollen die gespiegelten (kopierten) Seiten abgelegt werden. z.B. C:Users\fritz\Desktop\HTTrack
Daher ein Basisverzeichnis anlegen.
Mittels des Button rechts neben dem Eingabefeld kann man einen Speicherort direkt auf der Festplatte auswählen. 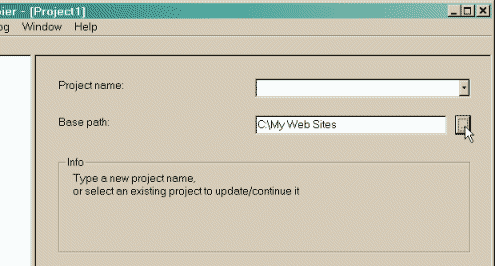 2 Wählen Sie den Namen des Projekts: Geben Sie dem Projekt einen eindeutigen Projektnamen Dieser Name sollte die URL der gespiegelte Websites sein, z.B. LINKSAMMLUNG 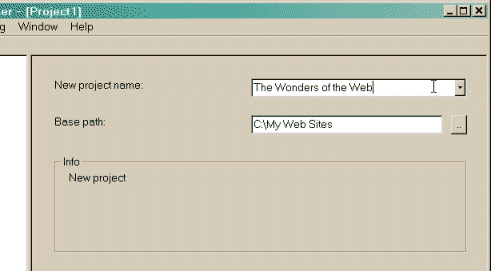 ODER Wählen Sie ein vorhandenes Projekt für Aktualisierung / Wiederholungs Wählen Sie direkt die bestehende Projektnamen in der Popup-Liste 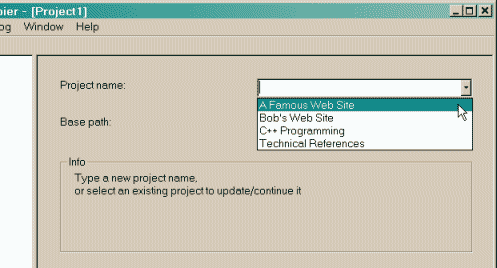 3 Klicken Sie auf die Schaltfläche [ Weiter > ] ************************************************************************** Schritt 2: Füllen Sie die Adressen 1 Wählen Sie eine Aktion Die Standardaktion zum kompletten Kopieren ist 1 Automatische Web-Site-Kopie
2 Web-Site-Kopie mit Rückfrage
3 Spezielle Dateien laden
4 Zu allen Links verzweigen (Kopie von mehreren Sites)
5 Links auf der Seite testen (Lesezeichen prüfen)
6 * Unterbrochenen Kopiervorgang fortsetzen
7 * Vorhandene Kopien aktualisieren wenn bereits lokale Kopien einer Webseite auf der Festplatte gespeichert sind um diese auf den aktuellen Stand zu bringen.
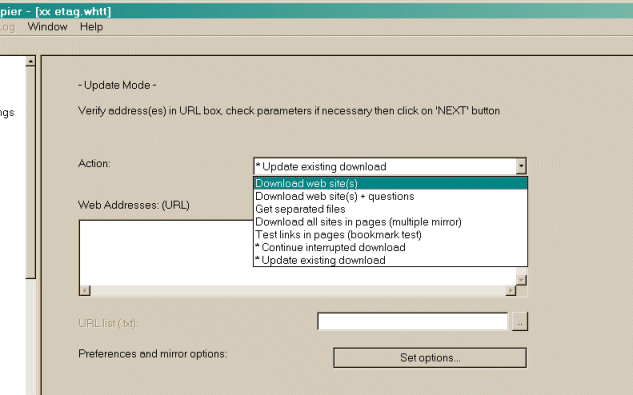 Download-Website ( s ) 1 Automatische Web-Site-Kopie Werden die gewünschten Seiten mit Standardoptionen transfert Download-Website ( s) + Fragen 2 Web-Site-Kopie mit Rückfrage Wird transfert die gewünschten Seiten mit Standardoptionen , und stellen Sie Fragen , wenn irgendwelche Links werden als potenziell als herunterladbare Holen Sie sich einzelne Dateien 3 Spezielle Dateien laden Wird nur die gewünschten Dateien (zB ZIP- Dateien) zu spezifizieren , aber nicht durch HTML-Dateien Spinne Laden Sie alle Websites in Seiten ( mehrere Spiegel ) 4 Zu allen Links verzweigen (Kopie von mehreren Sites) Werden alle Websites, die in der Website (s) ausgewählt erscheint herunterladen. Wenn Sie per Drag & Drop Ihre boormark Datei dieser Option können Sie alle Ihre Lieblings- Websites zu spiegeln Test- Links auf den Seiten (Bookmark -Test) 5 Links auf der Seite testen (Lesezeichen prüfen) Werden alle angezeigten Links testen. Sinnvoll, eine Bookmark-Datei überprüfen Weiter unterbrochenen Download 6 * Unterbrochenen Kopiervorgang fortsetzen Verwenden Sie diese Option, wenn ein Download wurde unterbrochen ( Benutzer Unterbrechung , Crash ..) Update verfügbaren Download 7 * Vorhandene Kopien aktualisieren Verwenden Sie diese Option, um ein vorhandenes Projekt zu aktualisieren. Der Motor wird erneut prüfen die komplette Struktur, die Überprüfung jedes heruntergeladene Datei nach Updates auf der Website 2 Geben Sie die Website -Adressen www.linksammlung.info Sie können auf das Web-Adresse (URLs) Eingabefenster klicken um die URL-Adresse hinzufügen. 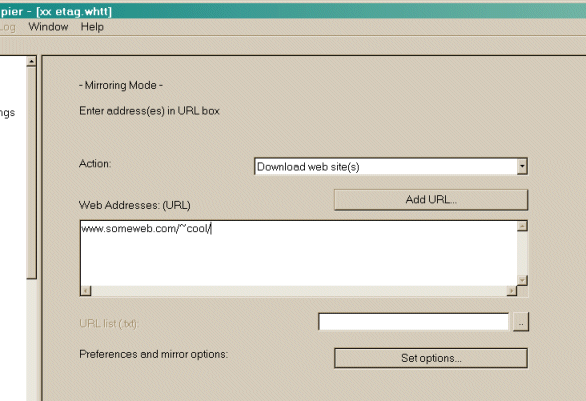 3 Sie können Optionen, Einstellungen und Kopieroptionen indem Sie auf die Schaltfläche [Einstellungen] klicken. Sie können Filter oder Download- Parameter in der Optionsfenster definieren 4 Sie können auch einen URL hinzufügen, indem Sie auf den Button [URL hinzufügen] klicken. Mit dieser Option können Sie zusätzliche Parameter (Benutzername Login / Passwort - leer lassen ) für die URL zu definieren, zu erfassen oder eine komplexe URL aus Ihrem Browser.
In dem sich geöffneten Fenster die URL-Adresse eingeben die man kopieren möchte.
5 Klicken Sie auf die Schaltfläche [ Weiter > ] ************************************************************************** Schritt 3: Startbereit 1 Wenn Sie möchten, können Sie sofort oder verzögern spiegeln (auf Festplatte kopieren)
o Bitte korrigieren Sie die Verbindungseinstellungen, wenn nötig
und klicken Sie auf "Fertig stellen", um den Kopiervorgang zu starten
1 Kein Remote-Access-Verbindung benutzen 2 Nicht mit Provider verbinden (schon verbunden)
[ ] Nach der Aktion Verbindung trennen
[ ] Shutdown PC when finished
Angehalten
hh mm ss O Nur Einstellungen speichern: Download jetzt nicht startenWenn Sie nichts auswählen, geht HTTrack davon aus, dass Sie bereits mit dem Internet verbunden sind und dass Sie das Spiegeln jetzt starten wollen. Verbindung zu diesem Anbieter Hier können Sie wählen einen bestimmten Anbieter zu wenden, wenn beginnend den Spiegel, wenn Sie nicht bereits mit dem Internet verbunden zu verbinden. Ziehen Sie, wenn Sie fertig Klicken Sie auf dieses Kontrollkästchen, um httrack fragen, um das Netzwerk zu trennen, wenn Spiegel ist beendet. Shutdown PC, wenn Sie fertig Klicken Sie auf dieses Kontrollkästchen, um httrack zum Herunterfahren Ihres Computers fragen, wenn Spiegel ist beendet. On Hold Hier können Sie die Verzögerungs-Zeit des Spiegels eingeben. Sie können bis zu 24 Stunden Verzögerung des Spiegel beginnes eintragen. 2 Klicken Sie auf die Schaltfläche Fertig stellen 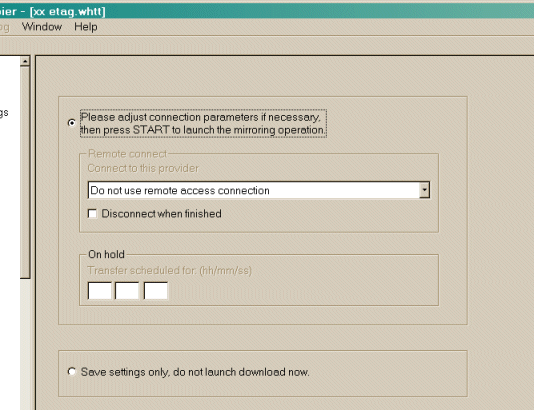 ************************************************************************** Schritt 4: Warten Sie! 1 Warten Sie, bis das Spiegeln (Kopiern) beebdet ist. Sie können jederzeit das Spiegel (Kopieren) abbrechen oder stornieren Dateien, die derzeit aus irgendwelchen Gründen heruntergeladen (Datei zu groß, zum Beispiel) Die Optionen können während der Spiegel geändert werden: maximale Anzahl von Verbindungen, Grenzen ... 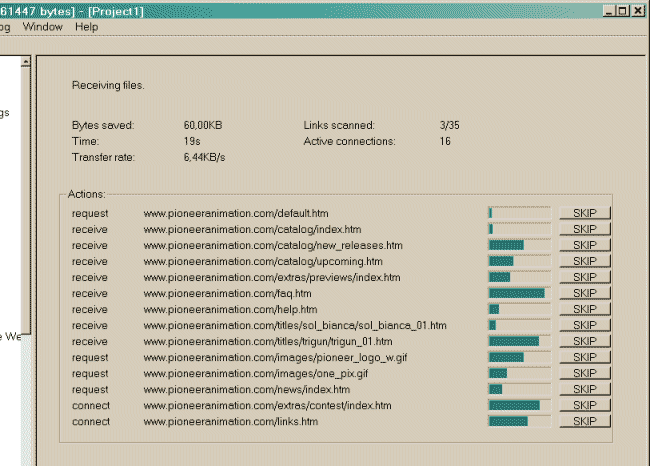
Während des gesamten Kopiervorganges sieht man in dem Fenster den Fortgang des kopierens.
Je nach Größe und Tiefe der Seite dauert der Kopiervorgang oft auch sehr sehr lang.
Spiegelung der Website läuft
In Bearbeitung: Analysieren der HTML-Datei
Transferring der HTML-Datei
anfordern, scannen, empfangen, verbinden, fertig
Information Transfering
Gespeicherte Bytes: 108,16 MBytes Bearbeitet 267/6722 (+6455)
Zeit: 3h Geschrieben 6340
Übertragungsrate: 0B/s (2,58KiB/s) Aktualisierte: 0
Verbindungen: 2, 1, none Fehler: 0
108Mbyte in 6.722 Dateien 5.Dez.2013
**************************************************************************
Schritt 5: Überprüfen Sie das Ergebnis 1 Überprüfen Sie Log-Dateien Ihnen kann die Fehlerprotokolldatei überprüfen, die nützliche Informationen enthalten könnte, wenn Fehler aufgetreten sind 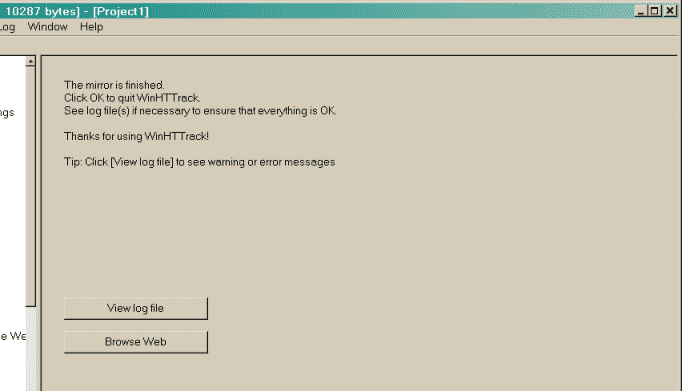
Fehlerprotokoll anzeigen Kopierte Seiten anzeigenSiehe die Seite Fehlerbehebung
Ist der Kopiervorgang abgeschlossen kann man mit der Option "Fehlerprotokoll" aufgetretene Fehler (z.B. ins leere laufende Links, nicht kopierte Elemente) anzeigen lassen.
Der Kopiervorgang weist immer irgendwelche Fehler auf das ist bei komplexen Internetseiten immer so. Ein Test der kopierten Seite zeig aber dann das die gewünschten Inhalte meist alle kopiert wurden.
Wählen Sie aber "Kopierte Seiten anzeigen" so wird der Internet-Browser gestartet und die lokale Kopie angezeigt.
Mit "Fertig stellen" kommt man zu Startbildschirm zurück und man kann eine neue Kopie starten.
Wählen Sie "Beenden" wird der HTTrack geschlossen.
Die lokal gespeicherten Kopien können jederzeit über den Datei-Browser gestartet werden.
Ins Projekt-Verzeichnis gehen und dort die Datei index.html mit Doppelklick öffnen.
Inhalte des Projekt-Verzeichnises
LINKSAMMLUNG
backblue.gif
fade.gif
index.html
LINKSAMMLUNG.whtt
In der Anzeige in der Adressleiste sehen Sie das es sich um eine lokale Kopie des Projektes LINKSAMMLUNG handelt da
file:///C:/Users/fritz/Desktop/LINKSAMMLUNG/www.linksammlung.info/index.html
zu finden ist.
**************************************************************************
Einstellungen und Kopierfunktionen: Einstellungen
Option-Panel Klicken Sie auf einen der Registerkarte Option unten, um mehr Informationen zu haben Jede Option Registerkarte beschrieben, einschließlich Anmerkungen und Beispiele.
7 Spider / 8 MIME-Typen / 9 Browser-ID / 10 Protokoll, Index, Cache / 11 Experten
1 Proxy / 2 Filterregeln / 3 Grenzwerte / 4 Flusskontrolle / 5 Verknüpfungen / 6 Struktur
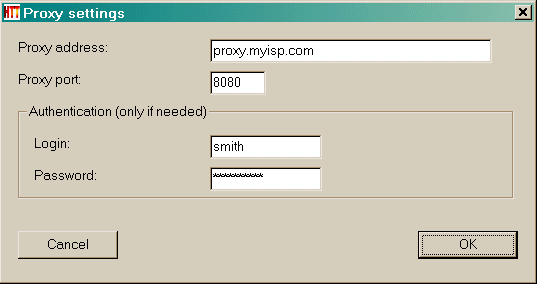
 Option-Panel: 1 Proxy Proxy: Konfigurieren [ o ] Proxy für FTP-Übertragung nutzen Passwort nicht anzeigen [ ]  Stellvertreter Sie können manuell die Proxy-Namen und den Port (geben Sie den Namen in das erste Feld, den Port in das zweite Feld) eingeben Über Proxy für FTP-Transfers Der Motor kann Standard-HTTP-Proxy für alle ftp (ftp://) Transfers zu nutzen. Die meisten Proxys erlauben das, und wenn Sie sich hinter einer Firewall befinden, wird diese Option können Sie leicht zu fangen alle FTP-Verbindungen. Außerdem sind FTP-Übertragungen vom Proxy verwaltet zuverlässiger als Standard-FTP-Client des Motors. Diese Option ist standardmäßig aktiviert Konfigurieren Klicken Sie auf diesen Knopf, um den Proxy konfigurieren. Wenn der Proxy-Authentifizierung braucht Sie können den Login-Benutzernamen / Passwort definieren
Proxy-Einstellungen
Proxy-Adresse:
Proxy-Port:
Authentifizierung (nur wenn benötigt)
Benutzername (Login)
Passwort
 Proxy: Konfigurieren [ o ] Proxy für FTP-Übertragung nutzen Passwort nicht anzeigen [ ] 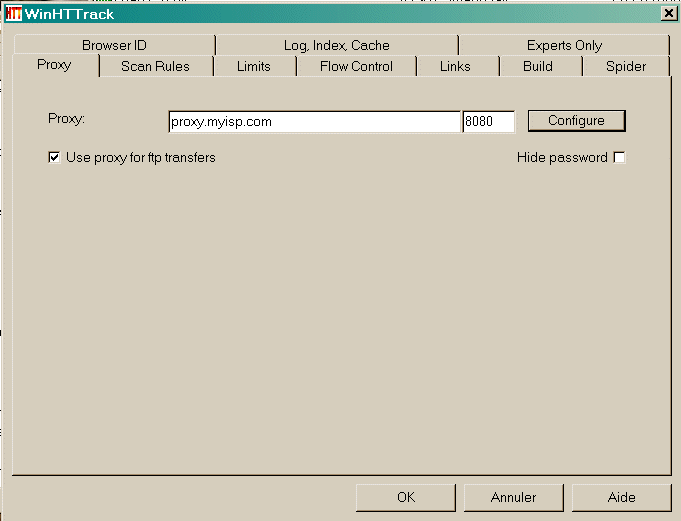 ausblenden vergessen Verwenden Sie es, wenn Sie nicht wollen, um das Passwort angezeigt (versteckt die Proxy-Name) Option-Panel: 2 Filterregeln
Verwenden Sie Platzhalter, um URLs oder verknüpfte Seiten ein- und auszuschließen.
Mehrere Filterregeln hintereinander müssen durch Leerzeichen getrennt sein.
z.B. +*.zip -www.*.com -www.*.edu/cgi-bin/*.cgi
[ ] gif, jpg, png, tif, bmp, [ ] zip, tar, tgz, gz, rar, [ ] mov, mpg, mpeg, avi, asf, mp3,
Links ausschließen +*.png +*.gif +*.jpg +*.css +*.js -ad.doubleclick.net/* -mime:application/foobar
Links einschließen
Tipp: Um ALLE GIF-Dateien einzuschließen, schreiben Sie z.B. +www.linksammlung.info/*.gif.
(+*.gif / -*.gif schließt ALLE GIFs auf ALLEN Seiten ein/aus
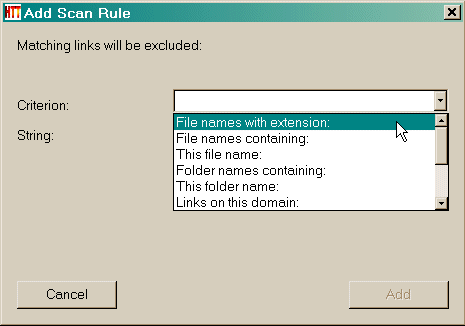
 Filter (Scan- Regeln ) sind die wichtigsten und mächtigsten Option, die verwendet werden können: Sie können Unterverzeichnisse ausschließen oder anzunehmen, springen bestimmte Arten von Dateien , und so weiter .. Wenn Sie fehlende Dateien (Bilder auf Top-Level- Verzeichnisse , zum Beispiel) mit Hilfe von Filtern können Sie helfen! Ausschließen link (s ) Mit dieser Taste können Sie einen Filter , um entweder ein Verzeichnis ausschließen , eine Domäne, einen bestimmten Dateityp hinzufügen ... Sehen Sie unten, um herauszufinden, wie man eine Filterregel hinzufügen ... Fügen link (s ) Mit dieser Taste können Sie einen Filter , um entweder ein Verzeichnis autorisieren , eine Domäne, einen bestimmten Dateityp hinzufügen ... Sehen Sie unten, um herauszufinden, wie man eine Filterregel hinzufügen ... Wie man eine Regel hinzufügen ( annehmen oder forbide Links) Wählen Sie eine Regel
WinHTTrack
Link(s) ausschließen
Link(s) einschließen
Filterregel hinzufügen
Auszuschließende Links:
Filterregel:
Schlüsselwort:
 Dann geben Sie den Suchbegriff (e) 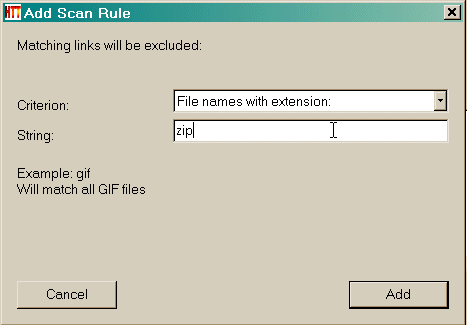 Klicken Sie auf die Schaltfläche Hinzufügen, um die Regel hinzuzufügen 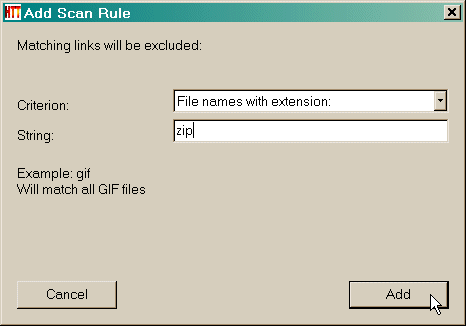 Ein weiteres Beispiel : Akzeptieren Sie eine bestimmte Verzeichnisnamen Angenommen, Sie haben eine Website, die Spiegelung an http://www.awondefulsite.com/mike/index/index.html , aber Sie können keine Bilder in / images / Landschaft / entfernt bekommen (zum Beispiel das Bild http://www. awondefulsite.com / images / Landschaft / bluewater.jpg nicht abgerufen wurde ) Wählen Sie eine Regel : in diesem Fall alle Artikel aus einem bestimmten Ordner Namen identifizieren 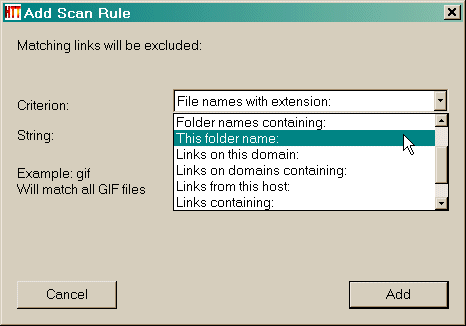 Dann geben Sie den Suchbegriff (e) : in diesem Fall ist es die Verzeichnisnamen ( ohne die Start-und End / ) 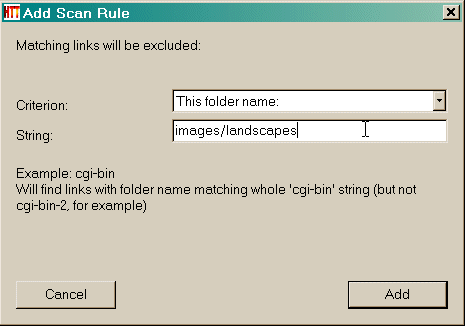 Klicken Sie auf die Schaltfläche Hinzufügen, um die Regel hinzuzufügen 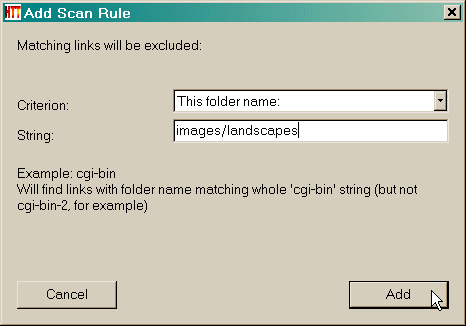 Die Regel wurde hinzugefügt 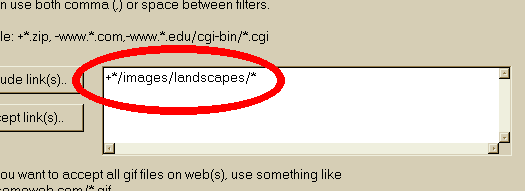 Siehe auch: Fortschritte Filter
Detto auch bei
Filterregel hinzufügen
Einzuschließende Links:
Filterregel:
Schlüsselwort:
Option-Panel: 3 Grenzwerte 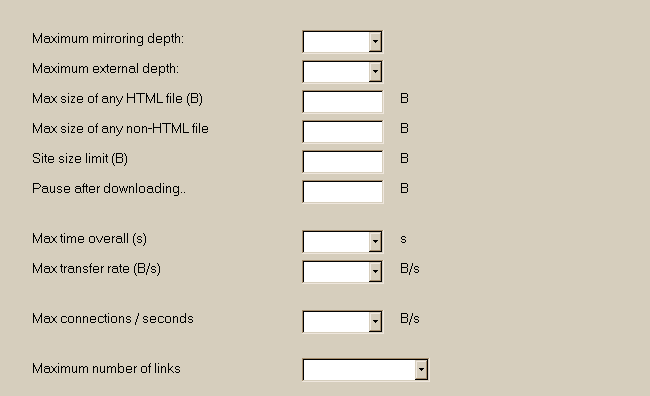 1 Maximale Tiefe: 2 oder 3 Definieren Sie, wie tief der Motor suchen in der Website eine Tiefe von 3 bedeutet, dass Sie alle Seiten, die Sie angegeben haben, zu fangen , sowie alle , die zugegriffen werden kann, klicken Sie doppelt auf einen Link Hinweis: Diese Option ist standardmäßig nicht gefüllt , so dass die Tiefe ist unendlich. Aber weil der Motor auf der Website, die Sie angedeutet bleiben, werden nur die gewünschten Websites gespiegelt werden , und nicht alle die Bahn ! 2 Maximale externe Tiefe: 1 Definieren Sie, wie tief der Motor suchen in externe Websites oder auf Adressen, die verboten waren . Normalerweise wird nicht HTTrack externer Webseiten standardmäßig (außer , wenn durch Filter autorisiert) zu gehen, und wird durch Filter -Adressen verboten vermeiden. Sie können dieses Verhalten zu überschreiben, und sagen Sie den Motor auf N Ebenen der "externen" Websites zu fangen. Hinweis: Verwenden Sie diese Option mit großer Sorgfalt , wie es überschreiben alle anderen Optionen ( Standard-Engine -Filter und Limiter ) Hinweis: Diese Option ist standardmäßig nicht gefüllt , so dass die Tiefe gleich null ist. 3 Maximale Anzahl Bytes von HTML-Dateien: B Definieren Sie die größten HTML -Datei der Motor erlaubt zu fangen. Diese Option ermöglicht es Ihnen, große Dateien zu vermeiden, wenn Sie nicht wollen, um sie herunterzuladen. 4 Max Größe einer Nicht-HTML- Datei: B Definieren Sie die größte nicht -html -Datei (Bild, ZIP-Datei, ..) der Motor ist erlaubt zu fangen. Diese Option ermöglicht es Ihnen, große Dateien zu vermeiden, wenn Sie nicht wollen, um sie herunterzuladen. 5 Max. Größe der Webseite (Site- Größenbeschränkung) B Begrenzt die Gesamtmenge von Bytes, die in der Stromspiegel heruntergeladen werden kann 6 Nach dem Download warten (Pause nach dem Download) B Diese Option ermöglicht der Motor eine Pause machen jedes Mal hat es eine bestimmte Menge von Bytes abgerufen Nützlich, wenn Sie eine Website -Spiegelung sind größer als der verfügbare Platz : Sie können dann Backup und während der Pause die heruntergeladenen Dateien löschen 7 Maximale Zeit (Gesamt) 10800 s Diese Option begrenzt die Gesamtzeit, des spiegelns (kopierens) 3h entsprechen 10.800 sec. 8 Maximale Übertragungsrate 25.000 bis 50.000 B/s Diese Option begrenzt die Übertragungsrate auf dem Stromspiegel Nützlich, wenn Sie nicht wollen, HTTrack , um die Bandbreite zu monopolisieren ! 9 Max. Anzahl Verbindungen pro Sekunde 10 cnx/s Begrenzt die Anzahl der Verbindungen pro Sekunde für die Stromspiegel. Diese Zahl kann eine schwimmende Zahl (z. B. 0,1 == 1 Verbindung pro 10 Sekunden) Nützlich, um die Serverlast zu begrenzen. Der Standardwert ist 10 , aber man kann es mit einem Wert von 0 zu deaktivieren - das ist nicht hingewiesen , wenn Sie wissen , was Sie tun ( Risiken der Serverüberlastung ) Höchstzahl der Links 100.000 Maximale Anzahl der Links, die analysiert werden können , das heißt, entweder heruntergeladen oder nicht heruntergeladen werden. Eine zu niedrige Grenze für diesen Satz nicht , denn wenn das Limit erreicht ist , wird der Motor sofort zu stoppen. Eine zu hohe Limit nicht , auch, weil es etwas Speicher zu nehmen .. 100.000 Links (Standard) ist in der Regel genug. Option-Panel: 4 Flusskontrolle
1 Anzahl Verbindungen
2 TimeOuts
3 Wiederholungen
4 Minimale Übertragungsrate (B/s)
[ ] Host aufgeben, wenn zu langsam
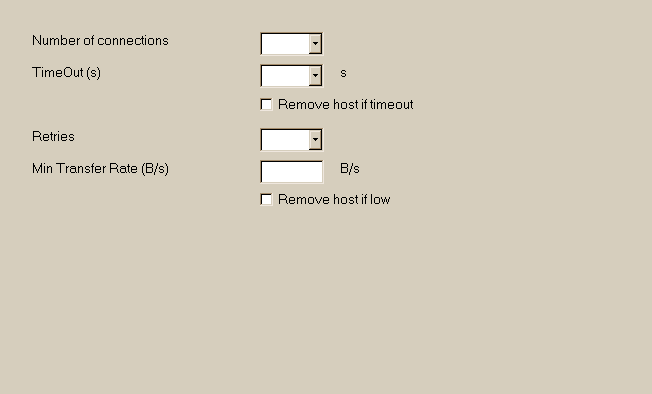 1 Anzahl Verbindungen Definieren die Anzahl der gleichzeitigen Verbindungen , die durch den Motor eingeleitet werden können . Es wird empfohlen , diese Zahl auf 1 oder 2 begrenzen, wenn Sie spiegeln große Dateien auf einer Website , mehr auf Standard- Websites (8 wird empfohlen , bis zu 42 , wenn sie durch das System unterstützt wird) 2 TimeOuts Definieren Sie, welche Zeit die Maschine warten muss, wenn keine Antwort , wenn sie von einem Server gegeben . 120 Sekunden empfohlen ( weniger schnell Rohre, mehr, wenn Sie Verbindung ist schlampig ) Sie können wahlweise alle Links von einem Host, der ein Timeout erzeugt hat, zu überspringen. Achtung: ist dieses Kontrollkästchen aktiviert ist, wird ein Timeout alle Links von den Ursprungsserver zu beseitigen 3 Wiederholungen Anzahl der Wiederholungen , wenn ein nicht schwerwiegender Fehler ist aufgetreten (Timeout , zum Beispiel) Beachten Sie , dass dies nicht fatale Fehler wie "Not Found" -Seiten und so weiter zu lösen! 4 Minimale Übertragungsrate (B/s) Mindestübertragungsrateauf einer Website toleriert. Wenn die Übertragungsrate , wenn langsamer , dass der definierte Wert, wird der Link wird übersprungen Sie können wahlweise alle Links von einem Host, der eine " zu langsam " Fehler erzeugt hat, zu überspringen. Achtung: ist dieses Kontrollkästchen aktiviert ist, ein " zu langsam " Fehler werden alle Links von den Ursprungsserver zu beseitigen Option-Panel: 5 Verknüpfungen
[ ] Alle URLs zu finden versuchen (auch in unbekanntn Tags und scripts)
[ ] Verknüpfte Nicht-HTML-Dateien laden (z.B. .ZIP oder Bilder von außerhalb)
[ ] Alle Verknupfungen teste (auch verbotene)
[ ] HTML-Dateien zuerst laden!
 Versuchen Sie, alle Links zu erkennen Fordert den Motor , zu versuchen, alle Links in einer Seite erkennen, auch für unbekannte Tags oder Javascript-Code unbekannt . Dies kann schlechte Wünsche oder Fehler in Seiten zu erzeugen , kann aber hilfreich sein , um alle gewünschten Links zu fangen Nützlich zum Beispiel in Seiten mit vielen Javascript Tricks Lass dich nicht- HTML-Dateien zu einem Link bezogen Diese Option können Sie alle Dateiverweise in HTML-Dateien erfasst , auch externe, fangen Zum Beispiel, wenn ein Bild in eine HTML-Seite ist mit seiner Source auf einer anderen Website , wird dieses Bild zusammen erfasst werden. Gültigkeit der Prüfung aller Links Diese Option zwingt den Motor , dass alle Links in spidered Seiten testen , dh zu überprüfen, ob jeder Link gültig ist oder nicht , indem eine Anfrage an den Server . Wenn ein Fehler aufgetreten ist , wird in das Fehlerprotokoll - Datei gemeldet . Nützlich für alle externen Links in einer Webseite zu testen Holen ersten HTML-Dateien ! Wenn diese Option aktiviert ist, wird der Motor versuchen, alle HTML-Dateien zuerst herunterladen und dann herunterladen andere ( Bilder )-Dateien . Dies beschleunigt den Parsing- Prozess , durch effizientes Scannen der HTML-Struktur . Option-Panel: 6 Struktur (build)
Strukturtyp (Wie Verknüpfungen gespeichert werden)
HTML in web/ , Bildr und anderes in web/images/
Optionen
1 [ ] DOS-Namen (8+3) 2 [ o ] ISO9660-Name (CDROM) wenn die kopierte Seite auf CD-ROM gebrannt werden soll anklicken
3 [ ] Keine Fehlerseiten
4 [ ] Keine externen Seiten
5 [ ] Paßwörter verbergen
6 [ ] Abfragetext nicht anzeigen
7 [ ] Alte Dateien nicht löschen
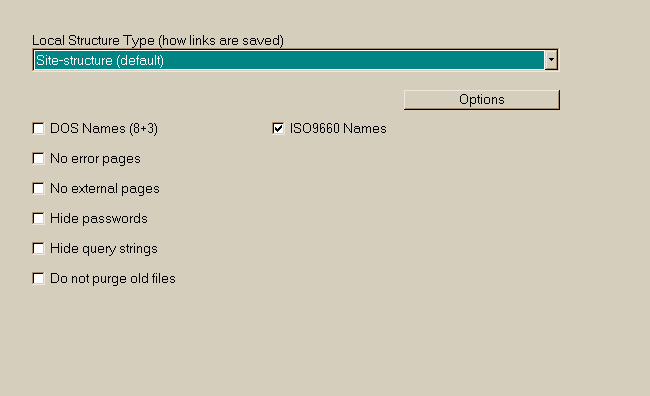 Lokale Strukturtyp Hier können Sie die lokale Struktur der Website zu definieren. Der Standardwert ist " Site-Struktur " : Sie werden die gleichen Ordner / Dateinamen und Struktur wie das Original erhalten Sie können jedoch alle Bilder in einem einzigen Ordner , html in einem anderen und so weiter .. 1 [ ] DOS-Namen (8+3) DOS- Namen Zwingen Sie den Motor auf DOS-Namen (8 Zeichen für den Namen , 3 für die Art ) erzeugen 2 [ ] ISO9660-Name (CDROM) ISO9660 Namen Zwingen Sie den Motor auf ISO9660 -kompatiblen Namen für die Speicherung auf Medien wie CD-ROM oder DVD-ROM erzeugen 3 [ ] Keine Fehlerseiten Keine Fehlerseiten Fehlerseiten nicht generieren (wenn ein 404- Fehler aufgetreten , zum Beispiel) Wenn eine Seite auf der Remote-Site fehlt, wird es keine Warnung auf der lokalen Website sein 4 [ ] Keine externen Seiten Keine externen Seiten Schreibt alle externen Links ( Links, die eine Internet-Verbindung benötigt ), so dass es eine Seite mit der Warnung vor sein ( "Warnung , Sie müssen online sein, um auf diesen Link zu gehen .. " ) Nützlich, wenn Sie , um die lokale und Online- Bereich trennen wollen 5 [ ] Paßwörter verbergen Passwörter ausblenden Fügen Sie keine Benutzernamen und Passwort für den geschützten Websites im Code , wenn ein Link nicht gefangen werden. Diese ermöglichen die Zugriffsdaten privat bleiben . 6 [ ] Abfragetext nicht anzeigen Abfragezeichen ausblenden Fügen Sie keine Abfragezeichenfolgen für die lokale Links . Abfragezeichenfolgen sind in der Regel nicht notwendig, für lokale ( file :/ / ) -Dateien, aber Query-Strings kann nützlich sein, einige Informationen zu zeigen (foo = 45 & bar = 67 ? ) (Beispiel : Seite 4.html - index = History) . Jedoch können einige Grund Browser nicht verstehen, dass (wireless Browsern , vor allem ) , und Verstecken Abfragezeichen vielleicht eine gute Idee in diesem Fall sein. 7 [ ] Alte Dateien nicht löschen Alten Dateien säubern Sie nicht Spülen Sie nicht , nach einem Update , die lokalen Dateien , die nicht mehr existieren auf der Remote-Site , oder die übersprungen wurden
Button Optionen
Benutzerdefinierte Struktur
%h%p%n%q%t
Optionen
%n Name der Datei ohne Dateityp (z.B. Bild)
%N Name der Datei mit Dateityp (z.B. Bild.gif)
%t Dateityp (z.B. gif
%p Pfad [ohne letzten /] (z.B. /Bilder)
%h Domainname (z.B. www.linksammlung.info)
%M URL MD5 (128 bits, 32 ASCII-Bytes)
%Q Abfragetext MD5 (128 bits, 32 ASCII-Bytes)
%q Kurzer Abfragetext MD5 (16 bits, 4 ASCII-Bytes)
%s? Kurzname DOS (ex: %sN)
Beispiel: %h%p%n%q%t
-> C:\Spiegelung\www.linksammlung.info\Bilder\Bild.gif
Option-Panel: 7 Spider
[ o ] Cookies annehmen
Dokumenttyp prüfen s
[ o ] JAVA-Datei analysieren
Spidr: s
[ o ] Aktualisierungstrick (Re-Transfers begrenzen)
[ o ] URL hacks (join similar URLs)
[ ] Tolerante Anfragen (für Server)
[ ] Alte HTTP/1.0-Anfragen erzwingen (nicht1.1)
 Cookies akzeptieren Accept Cookies durch den Remote-Server generiert Wenn Sie keine Cookies akzeptieren , werden einige "Session -generated "-Seiten nicht abgerufen werden Prüfen der Dokumenttyp Definieren Sie , wenn der Motor muss Dokumenttyp prüfen Der Motor muss den Dokumententyp zu kennen, die Dateitypen, neu zu schreiben. Zum Beispiel, wenn ein GIF-Bild ein Link namens / cgi-bin/gen_image.cgi erzeugt , die erzeugte Datei nicht " gen_image.cgi ", sondern " gen_image.gif " genannt werden Vermeiden Sie "nie" , weil die lokalen Spiegel könnten gefälschte sein Analysieren Java-Dateien Muss der Motor Parse . Java-Dateien ( Java-Klassen ), um eingeschlossene Dateinamen zu suchen? Es ist standardmäßig aktiviert Spinne Muss der Motor folgen Fern robots.txt- Regeln, wenn es sie gibt ? Der Standardwert ist "folgen" Update- Hack Versuchen Sie, Überweisungen durch Umwickeln bekannte gefälschte Antworten von Servern zu begrenzen. So wird beispielsweise Webseiten mit der selben Größe wie "up to date " angesehen werden , auch wenn die Zeitstempel scheint anders . Dies kann für viele dynamisch generierte Seiten , aber das kann auch nicht - aktualisierten Seiten in seltenen Fällen. tolerant Anfragen Tolerieren falsche Dateigröße , und stellen Sie Anfragen kompatibel mit alten Servern Es ist standardmäßig deaktiviert , da diese Option kann zu falschen Dateien zu werden Erzwingen alt HTTP/1.0-Anforderungen Diese Option zwingt den Motor HTTP/1.0-Anforderungen verwenden und HEAD-Anfragen zu vermeiden. Nützlich für einige Standorte mit alten Server-Versionen , oder mit vielen dynamisch generierten Seiten. Option-Panel: 8 MIME-Typen
Typ/MIME-Verknüpfungen
Dateitypen: MIME-Entsprechung:
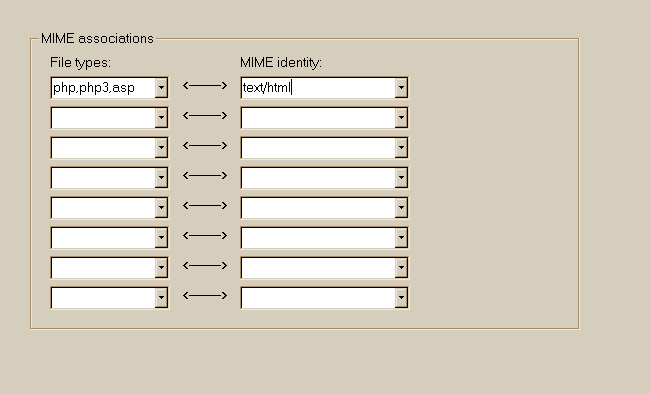 MIME-Typen Ein wichtiges neues Feature für einige Menschen. Diese Platte sagt der Engine , dass, wenn eine Verbindung gefunden wird, mit einem bestimmten Typ ( . Cgi, . Asp, oder . Php3 zum Beispiel) , muss er davon ausgehen, dass dieser Link hat immer die gleiche MIME-Typ , zum Beispiel die "text / html " MIME-Typ . Dies ist sehr wichtig zu beschleunigen viele Spiegel . Einige große HTML -Dateien, die viele Links von unbekannten Typs eingebettet ist, wie ". Asp " haben , bewirken, dass der Motor , dass alle Links zu testen , und das verlangsamt den Parser . In diesem Fall können Sie HTTrack sagen : " ASP-Seiten sind in der Tat HTML-Seiten. " Dies ist möglich mit Hilfe von : Dateityp: asp MIME Identität : text / html Sie können mehrere Definitionen erklären oder erklären, mehrere Arten von abgetrennt, damit "," wie in : Dateityp: asp , php, php3 MIME Identität : text / html Am wichtigsten MIME -Typen sind: text / html Html -Dateien , indem analysiert HTTrack image / gif GIF-Dateien image / jpeg JPEG-Dateien image / png PNG-Dateien application / x-zip . Zip-Dateien application/x-mp3 . MP3-Dateien application / x- foo . foo -Dateien application / octet-stream Unbekannte Dateien Sie können Dateien auf einem Spiegel umbenennen. Wenn Sie wissen, dass alle " dat "-Dateien sind in der Tat "zip" -Dateien in "dat " umbenannt , können Sie httrack sagen : Dateityp: dat MIME Identität : application / x-zip Sie können auch "name" einen Dateityp , mit seinem ursprünglichen MIME-Typ , wenn diese Art wird nicht von HTTrack bekannt. Dies wird ein Test zu vermeiden, wenn der Link zu erreichen: Dateityp: foo MIME Identität : application / octet-stream In diesem Fall HTTrack prüft nicht die Art , denn sie hat gelernt, dass "foo " ist ein bekannter Art , oder MIME-Typ "application / octet- stream" . Deshalb wird es die unberührte "foo" Art zu lassen. Option-Panel: 9 Browser-ID
Identität: (none) Mozilla/4.5 (compatible; HTTrack 3.0x; Windows 98)
HTML-Fußzeile: <!-- Mirrored from %s%s by HTTrack Website Copier/3.x [XR&CO'2013], %s -->
 Identität: Browser " Identität" Geben Sie hier den Namen der Engine, wie sie von Web - Servern zu sehen Zum Beispiel die Eingabe von " Mozilla/4.5 (compatible; MSIE 4.01 , Windows 98) " wird HTTrack in einen Standard- Browser zu tarnen MSIE4 Dieses Feld ist für statistische Zwecke , und Sie können eingeben , was Sie wollen , eine Browser-Namen , die nicht existiert oder sogar den Namen Ihres Oma Doch Vorsicht, dass mehrere Websites können einen anderen Inhalt , ob der Browser wird als " Netscape " oder "Explorer" zu liefern .. einige elitäre diejenigen noch weigern, etwas abhängig von der Browser-Namen zu liefern. Dieser Fall ist selten , zum Glück. HTML-Fußzeile Geben Sie hier die Optionnal Text, der als Kommentar in jedem HTML-Datei enthalten sein werden , um die Archivierung zu erleichtern Die eingegebene Zeichenkette ist in der Regel ein HTML-Kommentar (<- HTML-Kommentar - > ) mit Optionnal % s , die in eine bestimmte Zeichenfolge Informationen umgewandelt werden : % s # 1: Host-Namen (zum Beispiel www.someweb.com ) % s # 2: Dateinamen ( zB / index.html) % s # 3: Datum des Spiegels Beispiel: <- Seite von% s gespiegelt , Datei% s . Archiv Datum :% s -> Hinweis: Sie können (keine) auswählen , in diesem Fall keine Kommentare werden auf den Seiten hinzugefügt werden. Dies wird jedoch nicht empfohlen, da möchten Sie vielleicht in der Zukunft , wo die Seite getroffen wurde , wann / warum wissen .. Option-Panel: 10 Protokoll, Index, Cache
[ ] ALLE Dateien zwischenspeichern
[ ] Dateien nicht erneut laden, die lokal gelöscht wurden
[ o ] Protokolldateien
[ o ] Index erstellen
[ ] Wortliste anlegen
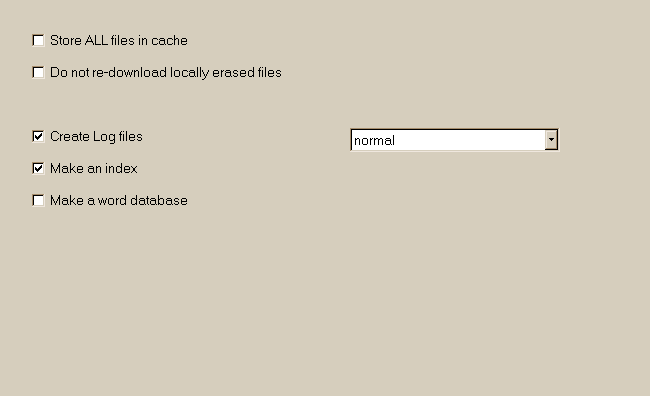 Zwingen, alle Dateien im Cache speichern Kraft , um alle Dateien im Cache , auch gif-Dateien , Zip-Dateien und so weiter speichern .. Ohne diese Option wird der Motor nur im Cache speichern html-Dateien für die Aktualisierung / Zweck weiter . Es kann nützlich sein , aber um alle Dateien im Cache zu halten, wenn Sie in der Zukunft , um die Website-Struktur ändern wollen Achtung! Diese Option wird deutlich aufblasen der Cache, der so groß wie der Spiegel selbst werden wird ! Nicht erneut herunterladen lokal gelöschten Dateien Diese Option verhindert, dass von HTTrack wieder fragen, eine Datei, die lokal mit Null- Größe vorhanden ist, oder dass durch den Benutzer gelöscht wurden (Wenn der Benutzer die Datei gelöscht , wird diese Option einen Null - Datei, um den Motor zu verhindern , um die Datei zu erstellen nächsten Zeit zu fangen ) Nützlich, wenn Sie das Löschen zunehmend große Dateien auf dem lokalen Spiegel und wollen nicht , um sie neu zu laden ! Erstellen von Protokolldateien Protokolldatei erstellen , wo Informationen , Fehler-und Warnungen über den Stromspiegel werden gespeichert Wenn Sie Protokolldateien erstellen , werden Sie nicht in der Lage zu wissen, was sein Fehler aufgetreten ! Es wird dringend empfohlen, diese Option aktiviert zu lassen Hinweis: Sie können den Debug -Level der Log - Dateien definieren. Der Standardwert ist "normal" Erstellen Sie einen Index Generieren Sie eine index.html auf der Oberseite des Verzeichnisses. Sehr nützlich . Machen Sie ein Wort -Datenbank Generieren einer index.txt Datenbank auf der Oberseite des Verzeichnisses. Sehr nützlich für die Sprachanalyse , wird diese Funktion können Sie eine Liste aller Wörter aller gespiegelt Seiten in das aktuelle Projekt. Mit diesem Index-Datei , können Sie zur Liste , welche Wörter erkannt wurden , und wo. Option-Panel: 11 Experten
Normalerweise sollten diese Einstellungen nicht geändert werden.
1 [ o ] Zwischenspeicher für Aktualisierungen benutzen
2 Haupt-Filterregeln
Alle Dateien speichern (Standard)
3 Suchmethode 4 Globale Suchmethode
Kann nach unten gehen (Standard) Bei Adresse bleiben (Standard)
5 Adressbezüge anpassen: intern / extern
Relative URL / Absolute URL (Standard)
6 [ ] Fehlersuch-Modus aktivieren (winhttrack.log)
 Tipps : Lassen Sie diese Optionen auf die Standardwerte ! 1 [ o ] Zwischenspeicher für Aktualisierungen benutzen Verwenden Sie einen Cache für Updates Diese Option muss gesetzt werden, wenn Sie die Site später aktualisieren möchten, oder wenn Sie die Gelegenheit, einen abgestürzten Spiegel weiter haben wollen Deaktivieren Sie es , wenn Sie nur wenige Kilobyte speichern möchten , aber , äh, wieder , ist es nicht ratsam, diese Option zu deaktivieren ! 2 Haupt-Filterregeln Primärfilter ( Scan-Modus ) Welche Dateien müssen gespeichert werden ? Sie können HTML- und / oder Nicht- Html zu wählen, oder keine ( diese letzte Option wird automatisch für das Scannen eingestellt )
Nur Verknüpfung analysieren
HTML-Dateien speichern
nicht HTML-Dateien speichern
Alle Dateien speichern (Standard)
Zuerst HTML-Dateien speichern
3 Suchmethode Reisemodus Legen Sie die Standard Spidern Richtung Standardmäßig werden alle Dateien in der gleichen Ebene und der unteren Ebene , das ist die logische fangen
Im selben Ordner bleiben
Kann nach unten gehen (Standard)
Kann nach oben gehen
Kann nach oben und unten gehen.
4 Globale Suchmethode Globale Reisemodus
Bei Adresse bleiben (Standard)
In Domain bleiben
In Top-Level-Domain bleiben
Freie suche überal im Web
5 Adressbezüge anpassen: intern / extern Stellen Sie die globale Standard Spidern Richtung Der Standardwert ist auf der gleichen Adresse bleiben, wenn keine spezifische Genehmigung geliefert wurde
Relative URL / Absolute URL (Standard)
Absolute URL / Absolute URL
Absolute URL / Absolute URL Unveränderte URL / Unveränderte URL 6 [ ] Fehlersuch-Modus aktivieren (winhttrack.log) Aktivieren Sie Debug-Modus Aktiviert zusätzliche Debug- Informationen , wie Kopf- Debugging- Schnittstelle und einige Informationen ( nur für Debugging- Zwecke ) ************************************************************************** Wie nicht zu verwenden Was Sie nicht tun dürfen: Bandbreite Missbrauch und andere schlechte Verhaltensweisen HTTrack Website Copier Open-Source- Browser offline Für HTTrack Nutzer : Beratung & was , wenn Sie mit HTTrack nicht zu tun Für Webmaster , die Probleme mit Bandbreite Missbrauch / andere Missbräuche zu HTTrack bezogen werden: Missbrauch FAQ für Webmaster Beratung & was nicht zu tun Bitte folgen Sie diesen gesunden Menschenverstand Regeln , jeden Netzwerk- Missbrauch zu vermeiden Überladen Sie die Webseiten! Das Herunterladen einer Website kann es überlasten, wenn Sie eine schnelle Rohr haben , oder wenn Sie zu viele gleichzeitige cgi ( dynamisch generierten Seiten) zu erfassen. Laden Sie keine zu großen Websites : Filter verwenden Verwenden Sie nicht zu viele gleichzeitige Verbindungen Verwenden Sie Bandbreitenlimits Verwenden Sie Verbindungslimits Verwenden Sie Größenbeschränkungen Verwenden Fristen Robots.txt Regeln nur mit großer Vorsicht zu deaktivieren Versuchen Sie nicht, während der Arbeitszeit downloaden Überprüfen Sie Ihre Spiegel Übertragungsrate / Größe Für große Spiegel, zunächst fragen, die Webmaster der Website Stellen Sie sicher, dass Sie die Website kopieren Sind die Seiten urheberrechtlich geschützt ? Können Sie sie nur für private Zwecke zu kopieren? Machen Sie keine Online- Spiegel , wenn Sie berechtigt sind , dies zu tun Überlasten Sie Ihr Netzwerk Ist Ihr ( Firmen-, Privat ..) Netzwerk über Einwahl- ISP verbunden ? Ist Ihre Netzwerkbandbreite begrenzt ( und teure) ? Sie verlangsamen den Verkehr ? Private Informationen zu stehlen Sie nicht E-Mails greifen Sie nicht Private Informationen greifen Sie nicht ************************************************************************** Missbrauch FAQ für Webmaster Wie Netzwerk- Missbrauch begrenzen HTTrack Website Copier FAQ (aktualisiert - ENTWURF ) Q: Wie man offline Browser, wie HTTrack blockieren? A: Das ist eine komplexe Frage , lassen Sie studieren Erstens gibt es verschiedene Gründe Warum willst du offline Browser blockieren? : Da ein großer Teil Ihrer Bandbreite wird von einigen Benutzern verwendet , die langsamer sind, den Rest Wegen Urheberrechtsfragen ( Sie wollen nicht die Menschen , um Teile Ihrer Website zu kopieren) Wegen der Privatsphäre ( Sie nicht wollen, E-Mail- Grabber , um alle E-Mails Ihrer Benutzer zu stehlen ) Missbrauch Bandbreite : Viele Webmaster sind besorgt über die Bandbreite Missbrauch, auch wenn dieses Problem durch eine Minderheit von Menschen verursacht. Offline- Browser -Tools wie HTTrack kann in einer falschen Weise verwendet werden , und sind daher manchmal als eine potenzielle Gefahr betrachtet. Aber vor dem Denken , dass alle Browser sind offline BAD , bedenken Sie: Schüler, Lehrer, IT-Berater , Websurfer und viele Menschen , die Ihre Website möchten, können wollen Teile davon zu kopieren, für ihre Arbeit, ihr Studium , zu lehren oder zu zeigen, den Menschen während des Unterrichts der Schule oder Shows. Sie könnten das tun , weil sie durch teure Modemverbindung angeschlossen sind, oder weil sie gerne auf Reisen Seiten konsultieren , oder Archiv-Seiten , die eines Tages entfernt werden kann , machen einige Data Mining, comiling Informationen (" wenn ich nur diese Webseite finden konnte Ich sah, 1 Tag .. "). Es gibt viele gute Gründe, Spiegel -Websites , und dies hilft, viele gute Leute . Als Webmaster können Sie daran interessiert sein könnten , solche Werkzeuge zu verwenden , auch: Test defekte Links , bewegen Sie eine Website zu einem anderen Ort , Steuerung, externe Links auf Ihrer Website für Rechts / content Kontrolle gestellt , testen Sie die Webserver- Antwort und Performances, indizieren .. Wie auch immer, kann die Bandbreite Missbrauch ein Problem sein. Wenn Ihre Website wird regelmäßig von bösen Downloader " verprügelt " , haben Sie verschiedene Lösungen . Sie haben radikale Lösungen und Zwischenlösungen . Ich bin der festen recomment nicht zu verwenden radikale Lösungen , denn von den bisherigen Ausführungen ( gute Menschen spiegeln oft Websites) . Im allgemeinen für alle Lösungen , die gute Sache : es wird die Bandbreite begrenzen Missbrauch das Schlimme : je nach Lösung , wird es entweder eine kleine Einschränkung oder ein fataler Ärgernis sein (Sie werden 0 Besucher zu bekommen ) oder, um es extrem: wenn Sie den Draht ziehen , wird es keine Bandbreitenmissbrauch Informieren Sie Menschen erklären, warum ( " bitte nicht, die Bandbreite zu verprügeln " ) Gut: Wird mit guten Leuten zu arbeiten. Viele gute Leute einfach nicht wissen, dass sie nach unten ein Netzwerk verlangsamen. Bad : Wird ** nur ** arbeiten mit guten Menschen How to do : Obvious - legen eine Notiz , eine Warnung , ein Artikel , ein Unentschieden , eine poeme oder was auch immer Sie wollen Verwenden Sie Datei " robots.txt " Gut: Einfache Einrichtung Schlecht: Leicht zu überschreiben Wie zu tun : Erstellen einer robots.txt-Datei auf dir , mit der richtigen Parameter Beispiel: User-agent: * Disallow: / Bigfolder Ban registrierte offline - Browser User-Agents Gut: Einfache Einrichtung Bad : Radikale und einfach zu überschreiben Wie man weiß : Filter der " User-Agent" HTTP -Header-Feld Begrenzen Sie die Bandbreite pro IP ( oder Ordner) Gut: Effiziente Bad : Mehrere Benutzer hinter Proxies werden verlangsamt , nicht wirklich einfach zu installieren Wie das geht : Je nach Webserver. Könnte mit Low-Level- IP-Regeln durchgeführt werden (QoS) Priorisieren kleine Dateien , gegen große Dateien Gut: Effiziente , wenn große Dateien die Ursache von Missbrauch Bad : Nicht immer effizient How to do : Abhängig von der Webserver Ban Täter IPs Gut: Sofort- Lösung Schlecht: Lästige zu tun, nutzlos für dynamische IPs und nicht sehr benutzerfreundlich Wie zu tun: Entweder verbieten IP in der Firewall oder auf dem Webserver (siehe ACLs) Limit- Täter IPs Gut: Mittelstufe und sofortige Lösung Schlecht: Lästige zu tun, nutzlos für dynamische IPs , und ärgerlich zu erhalten .. Die normalen QoS ( Fair Queuing ) oder Webserver- Optionen: Wie tun Verwenden technische Tricks ( wie JavaScript ), um URLs verbergen Gut: Effiziente Schlecht: Die effizientesten Tricks werden auch dazu führen, Ihre Website, um ihm schwer, und nicht benutzerfreundlich (und damit weniger attraktiv , auch für das Surfen Benutzer). Denken Sie daran: Kunden oder Besucher, möchten Sie vielleicht fragen offline Ihre Website . Fortgeschrittene Anwender werden auch weiterhin möglich sein, beachten Sie die URLs und fangen sie. Wird nicht auf nicht- javascript Browsern. Es wird nicht funktionieren , wenn der Benutzer klickt, und 50-mal setzen Downloads im Hintergrund mit einem Standard-Browser Wie zu tun: Die meisten Offline- Browser (ich würde sagen alle , aber wir sagen, dass die meisten ) sind nicht in der Lage zu "verstehen " javascript / java richtig . Grund: sehr schwierig zu handhaben ! Beispiel: Sie können ersetzt werden: <a href="bigfile.zip"> Foo </ a> von: <script language="javascript"> <! - document.write (' <a h' + ' re' + ' f = " '); document.write (' bigfile ' + + ' zip " >' '.') ; / / -> </ script> foo </ a> Sie können auch die java- basierte Applets . Ich würde sagen , dass es die " besten der Schrecken " . Ein großer, dicker , langsam, falsche Java-Applet . Vermeiden! Verwenden technischen Tricks, um Offline- Browser zurückbleiben Gut: Effiziente Bad : Kann durch fortgeschrittene Anwender vermieden werden , ärgerlich zu halten und potenziell schlimmsten , dass die Krankheit ( CGI oft nehmen einige CPU-Auslastung ) . . Es wird nicht funktionieren , wenn der Benutzer klickt, und 50-mal setzen Downloads im Hintergrund mit einem Standard-Browser How to do : Erstellen gefälschte leere Links, die auf die cgi darauf , mit langen Verzögerungen Beispiel: Verwenden Sie Dinge wie <ahref="slow.cgi?p=12786549"> <nichts> </ a> (Beispiel in PHP :) <? php for ($ i = 0; i < $ 10 , $ i + +) { Schlafstörungen (6); echo ""; } ? > Verwenden technische Tricks , um vorübergehend IPs verbieten Gut: Effiziente Schlecht: Radical ( Ihre Website wird nur für alle Benutzer online verfügbar sein ) , nicht einfach zu installieren Wie : Erstellen von gefälschten Links mit " Töten " -Ziele Beispiel: Verwenden Sie Dinge wie <a href="killme.cgi"> <nichts> </ a> (wieder ein Beispiel in PHP :) <? php / / IP hinzufügen. add_temp_firewall_rule ($ REMOTE_ADDR , " 30er "); ? > Funktion add_temp_firewall_rule ($ addr) { / / Die Kette chhttp in einem Cron-Job gespült, um ipchains Überlauf zu vermeiden System ( "/ usr / bin / sudo -u root / sbin / ipchains - I 1 chhttp - p tcp -s " $ addr " - dport 80 -j REJECT " . . ); syslog ( " Benutzer aufgrund zu vieler Kopie abgelehnt versucht sich :" $ addr . ); } ************************************************************************** Fragen des Urheberrechts Sie müssen nicht die Menschen zu "stehlen" Ihre Website oder sogar kopieren Teile es wollen. Erstens, Diebstahl einer Website nicht benötigen, um ein Offline-Browser zu haben. Zweitens ist manchmal direkt ( und gutgeschrieben ) Kopie besser als verschleierte Plagiat. Außerdem sind mehrere frühere Äußerungen auch interessant hier : Je mehr Ihre Website geschützt werden , die potentiell weniger attraktiv wird es auch sein . Es gibt keine perfekte Lösung , auch. Ein Webmaster , fragte mich eines Tages ihm eine Lösung für jede Website kopieren verhindern zu geben. Nicht nur für die Offline- Browser, sondern auch gegen "Speichern unter" , Ausschneiden und Einfügen , print .. und Druck-Anzeige. Ich antwortete, dass ist war nicht möglich, vor allem für die Druckanzeige - und dass eine andere potenzielle Bedrohung der böse Fotografen. Vielleicht mit einem " Dieses Dokument wird Selbstzerstörung in 5 Sekunden .. " oder durch Erschießen Benutzer nach Anhörung des Dokuments. Ganz im Ernst , einmal ein Dokument auf einer Website platziert , wird es immer die Risiken der Kopie (oder Plagiat) sein Um das Risiko zu begrenzen , frühere a- und h- Lösungen im Bereich " Bandbreite Missbrauch" , verwendet werden, Ruhe Könnte § 2 bezogen werden. Aber die größte Gefahr ist vielleicht E-Mail- Grabber . Eine Lösung kann sein, Javascript, verwenden, um E-Mails zu verstecken. Gut: Effiziente Bad : Non- Browser Javascript nicht die " klickbaren " Link haben How to do : Verwenden Sie Javascript, um bauen mailto : Links Beispiel: <script language="javascript"> <! - funktionieren FOS (Host, nom, info) { var s; if ( info == " " ) info = nom + "@ " + Host; s = "mail" ; document.write ( " <a href='"+s+"to:"+nom+"@"+host+"'> " + Info + " </ a> "); } FOS ( " mycompany.com ", " Schmied ? Subject = Hallo , John ", " Klicken Sie hier, um mir eine E-Mail ! ') / / -> </ script> <noscript> Schmied bei mycompany dot com </ noscript> Ein weiterer ist , um Bilder von E-Mails erstellen Gut: Effizient, nicht benötigen Javascript Schlecht: Es ist immer noch das Problem der Link (mailto :) Bilder sind größer als Text, und es kann zu Problemen für blinde Menschen verursachen (eine gute Lösung ist, verwenden Sie ein ALT -Attribut mit der E-Mail geschrieben, wie " Schmied bei mycompany dot com" ) Wie das geht : Nicht so offensichtlich, der Sie nicht wollen, um Bilder von sich selbst erstellen Beispiel: ( php, Unix) ************************************************************************** HTTrack Website Copier Lizenzvereinbarung : HTTrack Website Copier , Offline- Browser für Windows und Unix Copyright (C) Xavier Roche und anderen Mitwirkenden Dieses Programm ist freie Software und kann sie weitergeben und / oder modifizieren unter den Bedingungen der GNU General Public License wie von der Free Software Foundation veröffentlicht, entweder Version 3 der Lizenz oder einer späteren Version . Dieses Programm wird in der Hoffnung , dass es nützlich sein wird, aber OHNE IRGENDEINE GARANTIE, sogar ohne die implizite Garantie der Oder EIGNUNG FÜR EINEN BESTIMMTEN ZWECK. siehe GNU General Public License für weitere Details. Sie sollten eine Kopie der GNU General Public License erhalten haben zusammen mit diesem Programm , wenn nicht, schreiben Sie an die Free Software Foundation, Inc. , 59 Temple Place - Suite 330 , Boston, MA 02111-1307 , USA . Darüber hinaus als besondere Ausnahme , gibt Xavier Roche Erlaubnis, Verlinken Sie den Code dieses Programms mit der OpenSSL-Bibliothek (oder mit modifizierte Versionen von OpenSSL , die die gleiche Lizenz wie OpenSSL zu verwenden), verlinken und zu vertreiben , einschließlich der beiden. Sie müssen gehorchen die GNU General Public License in jeder Hinsicht für den gesamten Code verwendet, andere als OpenSSL . Wenn Sie diese Datei ändern , können Sie diese erweitern Ausnahme , Ihre Version der Datei , aber Sie sind nicht verpflichtet, zu tun so . Wenn Sie nicht wünschen , so zu tun , löschen Sie diese Ausnahme aus Ihre Version . Wichtige Hinweise : Wir bitten hiermit Menschen mit dieser Quelle nicht , um es in Zweck greifen verwenden E-Mails -Adressen oder sammeln keine andere private Informationen über Personen . Das würde unsere Arbeit zu blamieren , und verwöhnen die vielen Stunden, die wir dafür ausgegeben . Kontaktaufnahme / support : Bitte beachten Sie die Readme-Datei finden Sie ************************************************************************** HTTrack Website Copier Geschichte : -------------------------------------- In dieser Datei sind alle Änderungen und Updates, die für HTTrack vorgenommen wurden. 3,47-24 + Neu: Unterstützung für IDNA / RFC 3492 ( Punycode ) Handhabung + Neu: openssl nicht mehr dynamisch stratup sondiert , aber dynamisch verknüpften + Behoben: Zufalls Schließen von Dateien / Buchsen , was zu " zip_zipWriteInFileInZip_failed " Behauptung "Scheinstaat " -Nachrichten oder zufälligen Müll in heruntergeladenen Dateien + Behoben: libssl.dylib ist jetzt in die Suchliste für libssl auf OSX ( Nils Breunese ) + Behoben: Schein- Zeichensatz , weil die Meta http-equiv Tag ist zu weit in der HTML-Seite platziert + Behoben: falsche \ \ machine \ dir Struktur bauen auf Windows ( TomZ ) + Behoben: eine Datei nicht zwingen, eine Erweiterung haben , es sei denn es hat einen bekannten Typ (wie html ) oder eine möglicherweise bekannte Art (wenn verzögert Kontrollen sind deaktiviert ) + Behoben: HTML 5 hinaus über "Plakat "-Attribut für die " Video "-Tag (Jason Ronallo ) + Behoben: Speicherlecks in proxytrack.c (Eric Searcy ) + Behoben: das Z -Flag in hts-cache/new.txt Datei richtig eingestellt (Peter ) + Behoben: parallel Patch , typo über ICONV_LIBS (Sebastian Pipping ) + Behoben: Speicherleck in Hash-Tabelle , die zu übermäßigem Speicherverbrauch führen kann + Behoben: auf Windows , Fest möglich DLL lokale Injektion ( CVE- 2010 bis 5252 ) + Behoben: UTF-8 Konvertierung Fehler auf , die auf Linux -Buggy Dateinamen führen können + Behoben: Länge Null -Dateien nicht richtig behandelt (nicht auf der Festplatte gespeichert , nicht aktualisiert ) ( lugusto ) + Behoben: Fehler, der ernsthafte führen kann mehrmals die gleiche Datei downloaden , und " Unexpected 412/416 Fehler" Fehler + Behoben: Bilder in CSS wurden manchmal nicht richtig erkannt ( Martin) + Behoben: Links in JavaScript- Ereignisse wurden manchmal nicht richtig erkannt ( wquatan ) + Behoben: webhttrack verursacht Bus-Fehler auf bestimmten Systemen wie Mac OSX , aufgrund der Stack-Größe (Patrick Gundlach ) + Behoben: falsche Zeichensatz für Anforderungen, wenn Dateinamen Nicht-ASCII- Zeichen ( Steven Hsiao ) + Behoben: Schein- charset auf der Festplatte , wenn die Dateinamen nicht- ASCII-Zeichen ( Steven Hsiao ) + Behoben: Fest 260 - Zeichen -Pfad Grenze für Windows ( lugusto ) + Behoben: Nicht-ASCII- Zeichen Problem innerhalb Abfrage-String kodiert ( lugusto ) + Behoben: HTML-Entitäten nicht richtig in URI und Query-String decodiert + Behoben: URL - kodiert Frage im URI + Behoben: - timeout Alias hat nicht funktioniert + Behoben: mehrere Fenster spezifische Korrekturen bezüglich 260 -Zeichen- Limit Weg + Behoben: Flucht Problem in Top- Index + Behoben: Linux- Build- Bereinigung ( Gentoo -Patches zusammenzuführen, lintian Fixes et al.) + Behoben : Fest div durch Null bei der Angabe von mehr als 1000 Verbindungen pro Sekunde (wahrscheinlich nicht sehr häufig) + Behoben: Misshandlung von '+' in URLs in 3,47-15 ( sarclaudio ) eingeführt + Behoben: "Wildcard- Domains in Cookies nicht übereinstimmen " ( alexei dot co at gmail dot com) + Behoben: Buggy Referer beim Parsen : den Referer aller Links auf der Seite ist die aktuelle Seite analysiert wird , nicht die übergeordnete Seite . ( alexei dot com at gmail dot com) + Behoben: Russisch-Übersetzung Fixes von Oleg Komarov ( komoleg at mail dot ru ) + Neu: . Added torrent => application / x- bittorrent eingebauten MIME-Typ ( alexei dot co at gmail dot com) + Behoben: nicht in der Lage , auf eine URL einbettet , dessen Dateiname Sonderzeichen wie # ( lugusto ) herunterladen + Neu: Kroatisch -Übersetzung von Dominko aa ¾ Dajia ‡ ( domazd at mail dot ru ) + Behoben: url - Flucht in der vorherigen Subrelease eingeführt Regressions + Behoben: content-disposition NICHT berücksichtigt ( Stephan Matthiesen ) + Behoben: Buggy DNS Cache, um zufällige Abstürze führenden + Behoben: Fest Protokollierung nicht angezeigt robots.txt Regeln Grenzen standardmäßig + Behoben: Lizenz GPL Jahr und Link, libtool Korrekturen ( cicku ) + Behoben: Keywords Feld im Desktop-Dateien (Sebastian Pipping ) ************************************************************************** FAQ & Störungssuche Tipps : Im Falle von Schwierigkeiten / Probleme bei der Übertragung , überprüfen Sie zuerst die hts - log.txt ( und hts - err.txt )-Dateien , um herauszufinden, was passiert ist. Diese Protokolldateien berichten alle Ereignisse, die nützlich, um ein Problem zu erkennen sein können . Sie können auch den Debug-Level der Log-Dateien Berichtigung erfolgen in der Option Das Tutorial von Fred Cohen geschrieben wird, ist ein sehr gutes Dokument zu lesen, zu verstehen, wie man den Motor, wie die Kommandozeilen-Version funktioniert zu verwenden, und wie die Fenster -Version funktioniert , auch! Alle Optionen werden beschrieben und in klarer Sprache erklärt! Häufig gestellte Fragen zu HTTrack und Fehlerbehebung HTTrack erfasst nicht alle Dateien ! ! ! Allgemeine Fragen: Gibt es eine " Spyware " oder " Adware " in diesem Programm ? Können Sie beweisen, dass es nicht ? Diese Software ist "frei" , aber ich kaufte es von einem autorisierten Händler . Was ist los? Gibt es irgendwelche Risiken von Viren mit dieser Software ? Die Installation funktioniert nicht unter Windows ohne Administrator-Rechte ! Wo kann ich Detsch / andere Sprachen Dokumentation finden? Ist HTTrack Arbeit an Windows Vista / Windows Seven / Windows 8 ? Ist HTTrack Arbeit an Windows 95/98 ? Was ist der Unterschied zwischen HTTrack , WinHTTrack und webhttrack ? Ist HTTrack Mac-kompatibel ? Kann HTTrack auf allen Un * x kompiliert werden ? Ich HTTrack für professionelle Zwecke . Was ist mit Einschränkungen / Lizenzgebühr ? Gibt es irgendwelche Lizenzgebühren für die Verteilung einen Spiegel mit HTTrack gemacht ? Ist eine DLL / Bibliothek -Version? Gibt es eine GUI-Version für Linux und Un * x vorhanden? Fehlersuche: Einige Seiten sind sehr gut eingefangen , andere sind es nicht. Warum ? Wenn ich HTTrack , wird nichts gespiegelt ( keine Dateien ) Was ist passiert? Nur die erste Seite gefangen . Was ist los? Es fehlen Dateien ! Was ist passiert? Es gibt beschädigte Bilder / Dateien ! Wie kann man sie beheben? FTP- Links werden nicht erwischt! Was ist passiert? Ich habe einige seltsame Meldungen sagen , dass die robots.txt nicht erlauben mehrere Dateien erfasst werden. Was ist los? Ich habe doppelten Dateien ! Was ist los? Ich bin zu viele Dateien herunterladen ! Was kann ich tun? Der Motor dreht verrückt, immer Tausende von Dateien ! Was ist los? Datei umbenannt werden manchmal ( die Art geändert wird) ! Warum ? Datei werden manchmal falsch * * umbenannt ! Warum ? Wie kann ich benennen Sie alle . " Dat " -Dateien in " . Zip" -Dateien? Ich kann nicht auf mehrere Seiten ( Zugang verboten ist, oder leiten Sie an einen anderen Ort ) , aber ich kann mit meinem Browser , was ist los? Einige Seiten können nicht gesehen werden kann, oder mit Fehler angezeigt ! Die Dateien werden mit seltsamen Namen wie " - 1.html ' erstellt , ! Einige Java- Applets nicht richtig funktionieren ! Bei der Aufnahme von Real Audio / Video-Links ( . Ram) , erhalte ich nur eine Abkürzung! Mit Benutzer : Kennwort @ -Adresse funktioniert nicht! Sind https -URL funktioniert? IPv6- URL funktioniert? HTTrack ist zu viel Zeit für die Analyse ist es sehr langsam. Was ist los? HTTrack ist müßig für eine lange Zeit ohne transfering . Was ist passiert? Ich möchte eine Website zu aktualisieren , aber es ist zu viel Zeit ! Was ist passiert? Ich wollte eine Website zu aktualisieren , aber nach dem Update die Seite verschwunden ! Was ist los? Ich bin hinter einer Firewall. Was kann ich tun? HTTrack hat sich in einem Spiegel abgestürzt ist, was ist los? Ich möchte einen gespiegelten Projekt zu aktualisieren , aber HTTrack ist retransfering alle Seiten . Was ist los? Ich möchte einen gespiegelten Projekt fortsetzen, aber HTTrack Neueinlesens alle Seiten . Was ist los? WinHTTrack Fenster manchmal "verschwindet" dann am Ende in einer gespiegelten Projekt . Was ist los? Mit WinHTTrack , manchmal die Taskleiste zu minimieren, verursacht einen Absturz ! Fragen zum Spiegel : Ich möchte eine Website spiegeln , aber es gibt einige Dateien außerhalb der Domäne , zu. Wie man sie abrufen ? Ich habe einige URLs von Dateien während einer langen Spiegel vergessen .. Sollte ich alle wiederholen ? Ich will einfach nur , um alle ZIP-Dateien oder andere Dateien in eine Website in eine Seite abzurufen / . Wie kann ich es tun? Es sind ZIP-Dateien in eine Seite , aber ich weiß nicht, um sie zu übertragen. Wie kann ich es tun? Ich will nicht zu ZIP-Dateien größer als 1 MB und MPG- Dateien, die kleiner als 100 KB herunterladen. Ist es möglich ? Ich will nicht gif -Dateien zu laden .. aber was kann passieren, wenn ich mir die Seite ? Ich will nicht, Miniaturbilder herunterladen .. ist das möglich? Ich bekomme alle Arten von Dateien auf einer Website , aber ich habe sie auf Filter nicht auswählen ! Wenn ich Filter benutzen, bekomme ich zu viele Dateien ! Wenn ich Filter zu verwenden, kann ich nicht auf eine andere Domain , aber ich habe es gefiltert ! Muss ich eine "+" oder "-" in der Filterliste , wenn ich will , Filter benutzen? Ich möchte Datei (en) in einer Web-Seite zu finden. Wie kann ich es tun? Ich möchte ftp Dateien / FTP-Site herunterladen. Wie kann ich es tun? Wie kann ich abrufen. Asp oder . Cgi Quellen statt . Html Ergebnis? Wie entferne ich diese lästige <- ! Gespiegelte aus ... -> Aus html -Dateien? Muss ich mich zwischen ascii / binären Übertragungsmodus zu wählen ? Kann HTTrack führen formularbasierte Authentifizierung ? Kann ich umleiten downloads tar / zip -Archiv ? Kann ich Benutzername / Passwort-Authentifizierung auf einer Website ? Kann ich Benutzername / Passwort-Authentifizierung für einen Proxy ? Kann HTTrack erzeugt HP-UX oder ISO9660 kompatiblen Dateien ? Wenn es irgendwelche SOCKS unterstützt ? Was ist das hts - Cache-Verzeichnis ? Kann ich es entfernen? Was ist die Bedeutung der Verbindungen untersucht: 12/34 (+5) Linie in WinHTTrack / webhttrack ? Kann ich an einen Spiegel aus meinen Lesezeichen ? Kann ich konvertieren eine lokale Website ( file :/ / -Links) zu einem Standard- Website? Kann ich ein Projekt in einen anderen Ordner - Wird der Spiegel zu arbeiten? Kann ich ein Projekt auf einen anderen Rechner / System ? Kann ich dann aktualisieren? Wie kann ich E-Mail -Adressen greifen in Web-Seiten ? WinHTTrack / webhttrack (GUI-Version für Windows oder Linux / Unix) ************************************************************************** Download-Tool WinHTTrack Website Copier! - Webseitenkopierer Einstellungen Für einige Homepage kann es nützlich sein, sie komplett auf den eigenen Rechner zu spiegeln.
Geht die Seite vom Netz oder wie in meinem Fall Google sperrt grundlos die Seite ist alles weg.
Vorher sollten Sie natürlich erst einmal überprüfen, ob die Quelle überschaubar ist, sonst läd man sich bei einen der Mega-Portalen viel zu viel runter (und das meiste ist Schrott) oder man hat eine PHP-Seite gefunden, die einem immer wieder im Kreis schickt und man 1.000.000 mal die selbe Seite unter einem anderen Namen speichert. Gerade wenn man nicht weiß, wie lange eine Quelle noch offen ist, lohnt es sich, diese vorsichtshalber zu spiegeln, und bei Gelegenheit auf CD oder DVD zu brennen. Setup Download-Seite des Herstellers Für Windows-Anwender sind die ersten vier Links auf der Downloadseite zu empfehlen. Die Installation stellt keine Herausforderung dar. Man muss keine unerwünschte Toolbar fürchten und sich auch nirgends anmelden oder registrieren. Spiegelungder Webseite. 1. Starten Sie WinHTTrack. 2. Klicke auf [Weiter]. 3. In Projektname gibt man einen Projektnamen (und eventuell ein abweichendes Projektverzeichnis) ein. (sinnvoll die URL bzw. Internetadresse). 4. Projektkategorie bleibt leer, es sei den, man will eine abgebrochene Spieglung wieder weiterlaufen lassen. 5. Ein Downloadverzeichnis auf dem Rechner festlegen. Bei mir C:\Desktop\HTTrack und auf [Weiter] klickten. Aktion: Automatische Web-Site-Kopie 6. Bei den Aktionen braucht man in der Regel nichts umzustellen. 7. Kopiert die Seiten, die man gespiegelt haben will direkt in das offene Webadressen (URL) Eingabe-Fenster. Die Adresse der Startseite des Webs eingeben.
Wenn die Webs einen äußeren Fram besitzen, müssen Sie diese Adresse ermitteln.
Starten Sie dazu Ihren Webbrowser z.B. Mozilla Firefox öffnen Sie die Startseite dann klicken Sie mit der rechten Maustaste auf einen freien Bereich dieser Seite und dann gehen Sie auf Seiteninformation anzeigen, Sie sehen im Feld Adresse die eigentlicher URL dieser Seite.
URL markieren und in die Zwischenablage kopieren, dann in das Webadressen ( URL) Eingabe-Fenster kopieren.
(Bei kompletten Spieglungen reicht das Basisverzeichnis, doch Vorsicht, das kann nach hinten losgehen. Siehe oben) Bloß nicht gleich auf [Weiter] klicken 8. zuerst auf den Button [Einstellungen] klicken, und jeden einzelnen Karten-Reiter durchgehen.
[Experten]
Zwischenspeicher für Aktualisierungen nutzen.
Haupt-Filtereregeln: Alle Dateien speichern (Standard)
Suchmethode: Kann nach oben und unten gehen
Globale Suchmethode: In Domain bleiben
Adressbezüge anpassen intern/extern: Relative URL / Absolute URL (Standard)
a.) Proxi - In der Regel uninteressant b.) Filterregeln - Nützlich um Dateien ein- bzw. auszuschließen, und auch auf exotische Dateiendungen zu reagieren. Sinnvoll kann es sein Filme und und übergroße Dateien auszugrenzen. c.) Grenzwerte - GANZ WICHTIG sonst ladet ihr das ganze Internet auf euern Rechner. - Maximale Tiefe = (das ist der 1. Wert) nix eintragen, wenn man die komplette Webseite spiegeln will. Doch Vorsicht. Wenn man merkt das viel zu viel heruntergeladen wird, lieber abbrechen, und einen Wert von 5 bis Maximal 10 nehmen, damit keine Endlosschleifen vorkommen. Alle vorher gespeicherten Werte bleiben trotz Abbruch erhalten. (und auch die Dateien werden normalerweise nicht noch einmal herungergeladen). Man kann den Wert zur Not bei einem zweiten Durchgang nochmal erhöhen. - Maximale Tiefe = 2 Wenn man einzelne Seiten mit einem Direktlink zu Midi-Files oder ähnlichem hat. - Maximale Tiefe = 3 (-4) Wenn man Megaseiten kopieren möchte, und Ihr euch anhand von Navigationsseiten orientiert die ihr vorher in das Webseitenfenster bei Schritt 7. hineinkopiert habt. - Maximale Externe Tiefe = 0 (das ist der 2. Wert) Es sei den, ihr erwartet einen externen Verweis. Mit einer Verweistiefe von 1 oder 2 kann man gerade noch leben. Der Rest bleibt auf dem Reiter "Grenzwerte bei mir meist so wie er ist (meist leer). d.) Flusskontrolle = kann meist so bleiben wie es ist. Von Windows wird es in der Regel auf 4 begrenzt. Das "Keep Alive"-Häkchen sollte gesetzt sein. e.) [Verknüpfungen] Alle URLs zu finden versuchen (1. Häkchen) Besonders das "Bilder und Zip-Dateien" auch von außerhalb (2. Häkchen) sollte unbedingt gesetzt sein. Es kann sein, dass die Midis, Powertabs etc. auf einem anderen Server als die Homepage ist. Wenn ihr merkt, dass eine Bestimmte Dateiendung nicht mit runtergeladen wird, dann fügt diese ein. z.B. ptb, abc, crd, ... Alle Verknüpfungen testen (auch verbotene)) (3. Häkchen braucht man nicht anhaken)
HTML-Dateien zuerst laden (4. Häkchen)
f.) [Struktur] ISO9660-Name (CD-ROM) anklicken, sonst kann man später einmal keine CDs / DVDs brennen. g.) [Spider] = mache ich meistens nichts dran, und lass die ersten 4 Kästchen so angehakt wie sie sind und letzten 2 nicht angehakt. h.) Mime-Type = brauche ich so gut wie. Außer ich will, dass eine Dateiendung umbenannt wird. z.B. eine CRD-Datei in eine TXT-Datei oder Kar-Datei in Mid-Datei oder kar.mid (Karaoke-Datei = Midi mit Text) i.) Browser-ID j.) Browserprotokoll... k.) Experten ... lasse ich wie sie ist Jetzt auf [OK] klicken. Jetzt erst auf [Weiter] klicken Eine Remot-Acces-Verbindung habe ich bis jetzt noch nie gebraucht, und ob die Verbindung getrennt und der Rechner danach runtergefahren werden soll müsst ihr selber wissen. Achtet auf eure Online-Kosten (gerade wenn es unbeaufsichtigt endlos läuft) ! Eine Antivierensoftware soll immer am laufen sein ! ! ! Dann auf [Fertigstellen] klicken. Je nach Geschwindigkeit der Internetverbinung und größe der Seiten kann ein Download sehr lange (sogar über viele Stunden) dauern. Man kann aber immer abbrechen, und einen abgebrochenen Download wieder starten. Allerdings prüft HTTrack ob noch alle Seiten so sind wie sie waren. Bekannte Probleme: ▪ Seiten mit Zufallsfunktion: Komponente Forum. Hier kann es zu einer Endlosschleife kommen. Abhilfe: Forum während des Grabbens aus der Liveversion entfernen. • Quick Access Dropdown ist ind Offline Kopie zwar vorhanden aber ohne Funktion. • Bilder werden nicht gespeichert, wenn im Template die Function "zeige_bild.asp" für Bildanzeige verwendet wurde. Abhilfe: Diese Funktion im Template nicht verwenden • Die Suche funktioniert in einer Offline Version nicht, da kein Server zur Verfügung steht. • Es kann vorkommen, dass 2 Grabdurchläufe notwendig werden. **************************************************************************
DIN A4 ausdrucken
********************************************************I*
Impressum: Fritz Prenninger, Haidestr. 11A, A-4600 Wels, Ober-Österreich, mailto:[email protected]ENDE a |